聚合页广告将商家和优惠信息以多种形式聚合展示给用户,是美团广告业务中一个重要的业务场景。本文从最能影响用户决策的“发券”和“排序”两个方向出发,介绍了上下文感知建模在广告场景的落地方案,证明了聚合页上下文感知的收益空间。希望能对从事相关研究的同学带来一些启发或帮助。
聚合页广告是美团一个重要的业务场景,我们将商家和多种优惠以聚合的形式展示给用户。如下图1所示,聚合页通过多种发券模式吸引用户下单。上下文信息建模是聚合页实现精准个性化匹配的重要途径,我们从上下文信息中选择了最能影响用户决策心智的“发券”和“排序”两个方向进行了深入探索:
下文实践一和实践二将具体介绍我们在这两项工作中面临的技术挑战和创新性解法。
在电子商务平台的精准营销实践中,营销干预策略(Treatment)的设计与效果评估是提升用户参与度和商业价值的关键环节。常见的干预手段包括定向广告、限时折扣和智能优惠券发放等,这些策略通过影响用户行为实现商业目标。作为因果推断在营销领域的核心应用,Uplift模型通过预测个体处理效应(Individual Treatment Effect, ITE)来解决策略效果异质性问题——即量化特定干预(如某类优惠券)对目标用户的增量转化效果,从而构建”零资源浪费”的精准营销系统。
与传统监督学习不同,Uplift建模本质上是反事实推理问题:需要同时估计用户在干预组(T)和对照组(C)的潜在结果。现有主流方法采用多响应建模框架,典型代表包括:构建单一特征映射函数估计各干预下的条件平均结果的S-learner,以及在此基础上的几个变体,例如X-learner、T-learner等,各种深度学习方法以其卓越的特征提取能力作为Uplift框架的基本模型。然而这些方法仍然存在两个问题:

为了解决上述问题,我们提出了一种上下文增强的全链路Uplift建模方法(ECUP),旨在提升Uplift建模的准确性。

据此,我们计算了CTCVR(曝光空间)和CVR(点击空间)的实际Uplift值。如下图所示,CTCVR和CVR在不同段的变化趋势并不完全一致,这表明不能仅通过点击集上的CVR提升来推断全链路的实际Uplift。这种现象的主要原因是用户在不同阶段的行为关注点不同,导致Treatment对行为的影响在链路各阶段存在差异。因此,我们提出在全链路空间中构建Uplift模型,并引入任务先验信息,以精准捕捉Treatment对不同任务的影响,从而解决链路偏差问题。

ECUP模型整体结构如下图所示,主要由两部分组成:1.全链路增强网络(ECENet),使用用户的序列模式来估计整个链路空间中每个任务的结果,并使用任务增强网络(TAENet)注入任务先验信息以实现上下文表征,捕捉每个任务上的不同uplift,以避免链路偏差的负面影响。2.Treatment增强网络(TENet),旨在引导初始特征的Treatment感知细化,并实现不同Treatment下embedding表征的bit级别自适应调整,以解决Treatment不适应问题。
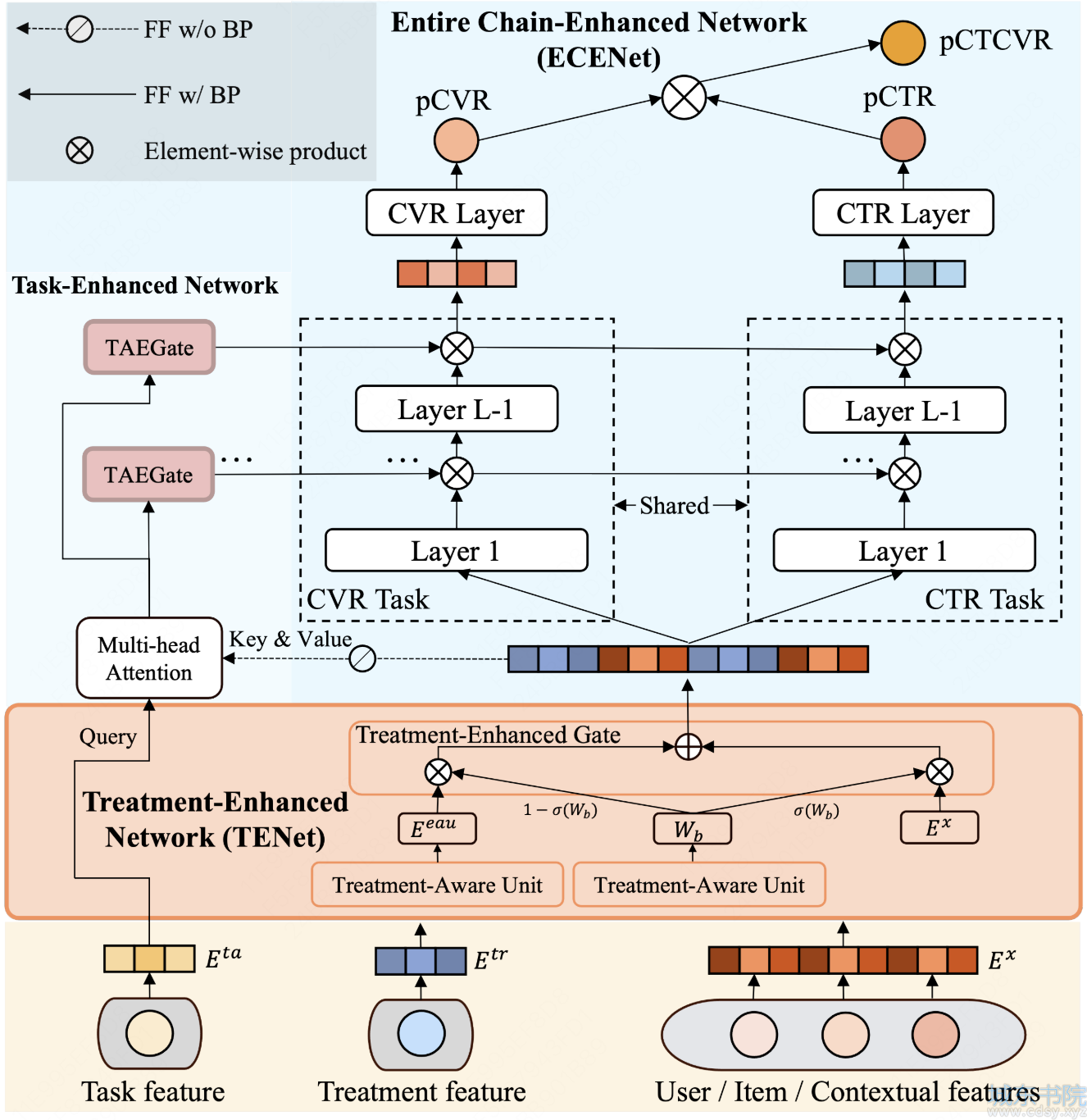
全链路增强网络(ECENet)
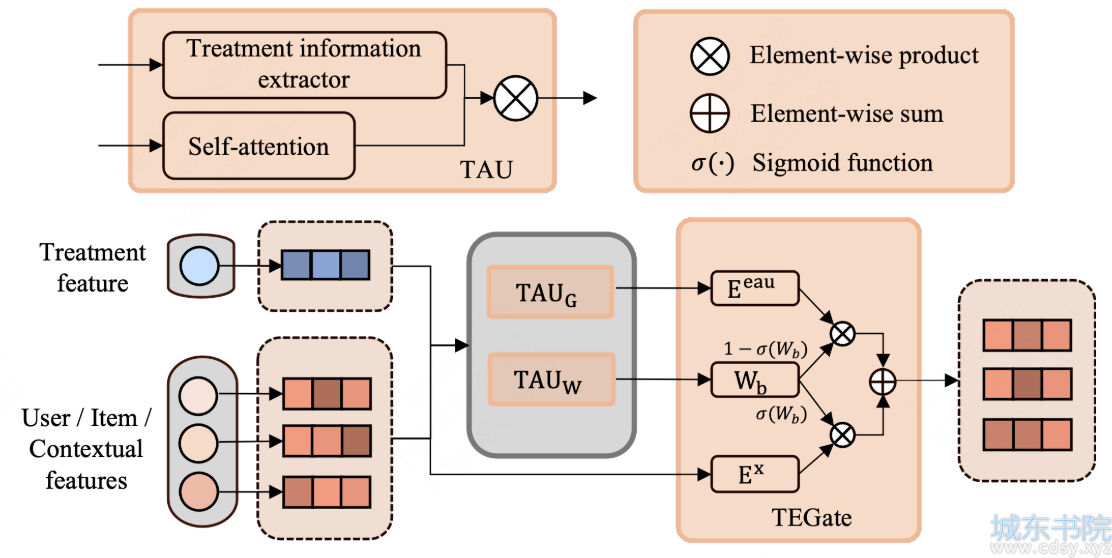
在特定Treatment中,个体对不同任务的响应存在差异。此部分的目标是在捕获任务感知特征表达,传统方法通过多个塔来学习多任务目标的方法表达能力有限,无法捕捉Treatment对不同任务的不同影响。为此,本文提出任务增强网络(TAENet, Task-Enhanced Network),以深度融合任务先验与Treatment增强表示(TENet的输出),实现上下文增强的参数学习。TAENet通过个性化选择和调整DNN参数,平衡不同上下文中特征的稀疏性。
具体而言,TAENet使用门控机制结合任务先验信息,自适应地获取DNN每层的参数。任务信息作为先验输入,通过多头注意力网络建模为Treatment增强的Embedding表征。为保证初始特征和Treatment Embedding的稳定性,训练时仅更新任务表征。在此过程中,任务信息作为注意力网络中的Query,而Treatment增强表征作为Key和Value,用于捕获上下文增强的先验信息。

接着,将先验信息注入到MLP结构的门控机制中,门控机制的输出结果和每个DNN塔的每层(最后一层除外)结果点乘,实现自适应参数选择。

我们共享除了各任务最后一层的所有参数。我们在模型训练中使用pCTR和pCTCVR来计算整个样本空间的损失,损失函数为交叉熵:

参数共享机制显著降低了数据稀疏性对后续任务的影响,而TAEGate模块则确保模型在共享参数的同时,能够精准捕捉Treatment对每个任务的差异化影响。
Treatment增强网络(TENet)

为了全面评估所提出的方法,我们收集了聚合页在为期两个月的优惠券营销场景中的数据,并按一定比例随机抽取形成了最终的数据集。该数据集包含多种Treatment方法和全链路标签信息,通过随机对照实验收集,以确保Treatment组和对照组之间的潜在分布一致,从而消除混杂因子对Uplift建模的影响。数据集包含近550万个实例、99个特征、Treatment信息以及两个标签:点击和转化。

我们在公开数据集和美团数据集上做了实验,用AUUC和QINI衡量uplift模型效果

此外,通过消融实验证明各板块重要性。

最后,我们在业务上进行了A/B实验,取得了显著的收益。

重排通过重新排列初始排名列表,在现代多阶段推荐系统中发挥着至关重要的作用。由于组合搜索空间这样的固有挑战,当前的一些研究采用了评估器-生成器范式,生成器生成可行的序列,评估器评估并选择最佳的序列。然而这些方法仍然存在两个问题:
为了解决这些问题,我们提出了一个利用邻域列表的重排方法(NLGR),旨在提高生成器在组合空间中的生成效果。
NLGR遵循评估器-生成器范式,并改进了生成器的训练方式和生成方式。具体来说,我们使用组合空间中的邻居列表去增强生成器的训练过程,使生成器能感知相对分数并找到优化方向。 进一步,我们提出了一种新颖的基于采样的非自回归生成方法,它可以使生成器灵活地从当前列表跳转至任意邻居列表。模型结构如下图所示,左侧是评估器,中间是生成器,右侧是细节结构。
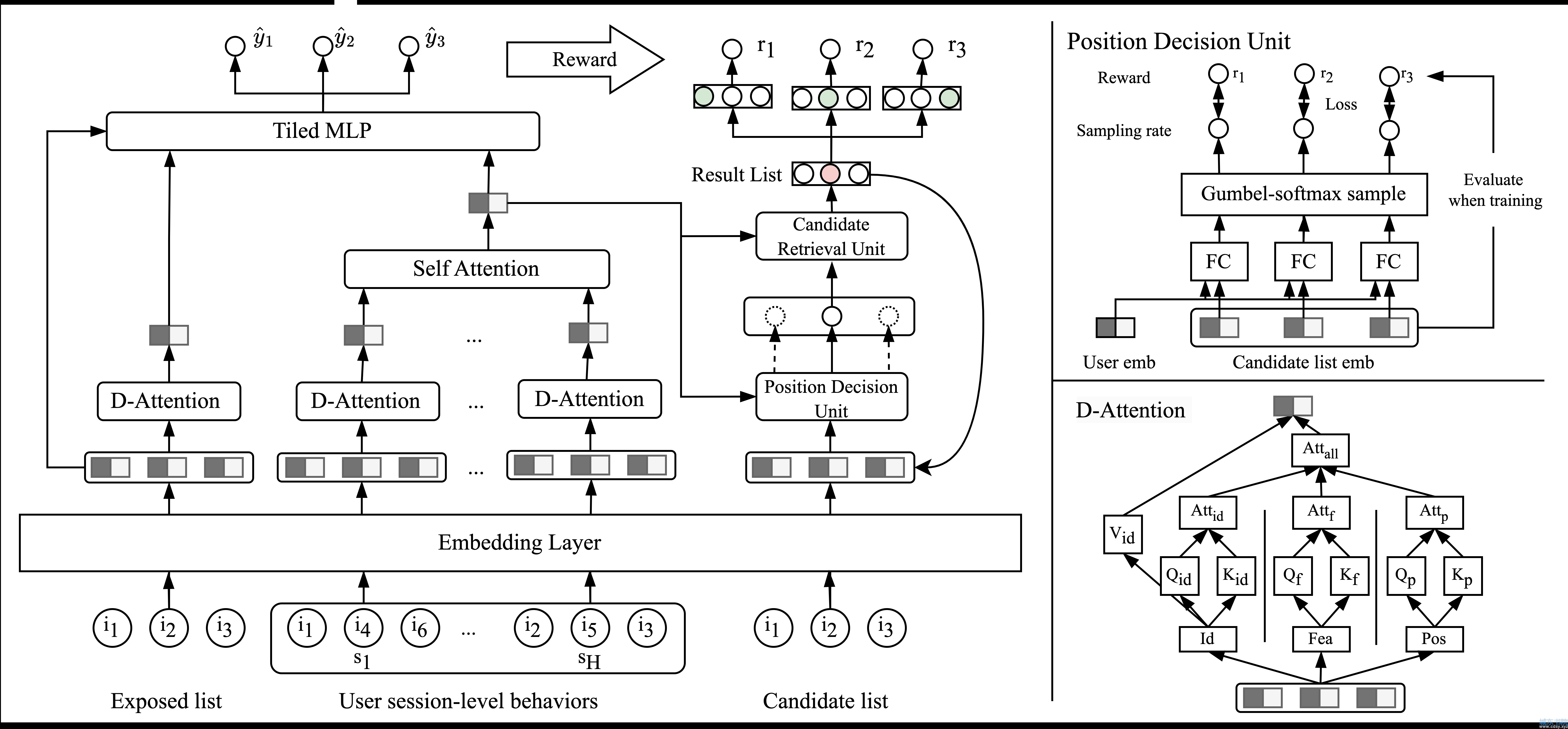
评估器
生成器评估任意一个候选列表。输入主要包括候选列表和用户历史session-level的行为(其他的特征没有列出来),然后经过特征提取后送入预估层(MLP)进行预估,预估层的输入包括四部分:j-th项目的emb、候选列表的emb、从用户历史行为提取出来的用户emb和j-th的位置emb。

生成器
生成器将任意一个候选列表生成为排列空间中的最优列表。生成过程分为2步,先从候选列表中决定要替换的位置(PDU),再从剩余候选项目中挑选出一个项目放入候选列表中(CDU)。
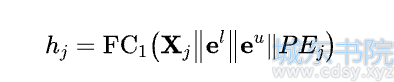
在训练时为了保证梯度传播,用gumbel-softmax采样,得到要替换的位置:


同样的,在训练时为了保证梯度传播,用gumbel-softmax采样,得到要插入的候选:

邻居训练
评估器采用常规的交叉熵损失:

重点在生成器的训练方式。依次替换候选列表每个位置上的项目,构造邻居列表,评估邻居列表的reward,与候选列表reward的相对值作为生成器的reward:

邻居列表的Reward也可以用来指引PDU的训练:

我们在公开数据集和美团数据集上做了实验,用auc衡量评估器效果,用hit ratio衡量生成器效果。

其实我们更加关注生成器的效果,hit ratio衡量了“生成器能发挥多少评估器的能力”。

我们在业务上进行了A/B实验,取得了显著的收益。

聚合页广告将商家和优惠以多种形式聚合展示给用户,聚合页的上下文信息建模是实现精准个性化匹配的重要途径。我们从最能影响用户决策心智的“发券”和“排序”两个方向进行了深入探索,取得了显著的收益,证明了聚合页上下文感知的收益空间。未来,我们将继续深化算法优化。对于发券,我们会探索更高效的反事实去偏方法,减少对随机样本的依赖;也会增加考虑券预算浮动并保证券成本稳定的建模。对于排序,我们会探索具有全局视野的生成/评估式方法,克服重排的组合空间搜索难题。此外,LLM与全链路上下文的结合也是未来的探索方向之一。












 湘公网安备 43102202000103号
湘公网安备 43102202000103号