忽然有兴趣想试试把某网络小说网站上所有的小说都给爬下来。就拿17K小说网开刀,先把这个网站免费排行榜上的所有小说都弄下来。
之前发过贴,如何将一本小说爬取出来,以及简单规避网站安全系统。这次爬取多本的话,无非是在最外层再加一个循环,然后以多线程的方式启动,对每一部小说进行爬取,就不描述的太具体了。
完整代码在最后。
依然是python3+pycharm,安装第三方库requests、threading
- import os
- import requests
- import re
- import time
- import random
- import threading
-
17K小说免费排行榜地址:
https://www.17k.com/top/refactor/top100/06_vipclick/06_click_freeBook_top_100_pc.html.
依然是先写好方法,获取html。最好是将html打印到本地,便于观察html,找出小说url的正则规律
- #获取网页html
- def get_htmlcode(url):
- try:
- urlhtml = requests.get(url)
- htmlcode = urlhtml.content
- # path = open('Txt/html.txt','wb')
- # path.write(htmlcode)
- # path.close()
- except:
- htmlcode = 'error'
- return htmlcode
-
加一个try是为了避免网站服务出现问题导致程序跑不过。
通过对html进行分析,以 <a class=“red” href=" 开头、 " title=’ 结尾,中间的部分就是各小说的url。
对正则后的列表进行统计数量,发现爬取出了900个小说url。当时很震惊,明明是top100 ,为什么爬了900个?开始还以为是自己正则的规律选错了。后来对网站进行审查,发现这个top 100分男生、女生、全站三大类,每个大类里又细分了周榜、月榜、总榜。3乘以3,正好是900。只不过这个时候就需要对爬取的900个url进行去重了,最后获得了408个小说地址。
但是此时的url还不是完整url,缺少了https前缀。
同时还需要将每个小说url中的book替换成list,这样就是每个小说的章节目录地址了。
- #获取所有免费top榜的txt地址,去重,再完善地址路径
- def get_topfree_list(htmlcode):
- reg = '</a></td><td><a class="red" href="(.+?)" title='
- reg_msg = re.compile(reg)
- list_all = reg_msg.findall(htmlcode.decode())
- #去重
- list_temp = list(set(list_all))
- list_top = []
- #完善地址,加上https前缀,并将book替换成list
- for i in list_temp:
- i = 'https:'+ i
- i = i.replace('book','list')
- list_top.append(i)
- return list_top
-
上一部获取了所有小说的章节目录地址了,并存在了一个列表中。我们只要对这个列表进行遍历,再从章节目录地址的html中去获取每一章的地址,最后再遍历每一章的地址,从html中去得到小说的正文。这样就对得上了。
这一步的具体过程在上个帖子中已经具体介绍过了,就不细说了。
另这个网站很奇怪,虽说是免费榜,但是有的小说的部分章节又被锁住了,导致咱们在按照正则去获取章节名和小说正文时,因为匹配不到而报错。好在绝大部分锁住的章节html中规律还是比较明显的,就是会出现"该章节已被锁定"这些字眼,于是加了这么个方法:
- #判断是否被锁定
- def insert_lock(htmlcode):
- str1 =htmlcode.decode()
- str2 ='<h1>该章节已被锁定</h1>'
- temp = str1.find(str2)
- return temp
-
当返回的值不为-1时,则证明没有被锁定。
此步骤完整代码
- #从小说章节列表地址到爬取完成
- def get_novel_all(chapter_url):
- # 章节列表网站的html
- Htmlcode_chapter_list = get_htmlcode(chapter_url)
- if Htmlcode_chapter_list == 'error':
- print('~~~~~~~~~~~~~17K小说地址出错了:%s,请稍后再试~~~~~~~~~~~~~'%chapter_url)
- else:
- # 获取小说名称
- Novel_name = get_novel_name(Htmlcode_chapter_list)
- Novel_name_str = str(Novel_name)
- # 从源码中匹配出所有章节的地址
- Chapter_list = get_chapter_list(Htmlcode_chapter_list)
- # 创建TXT文件并打开
- path = open('17k/' + Novel_name_str + '.txt', 'a',encoding='utf-8')
- # 写入小说名称
- path.write('~~~~~~%s~~~~~~' % Novel_name_str)
- path.write('\n\n\n')
- flag = 0
- # 循环处理每个章节地址
- for l in Chapter_list:
- # 逐一处理章节地址,加上前缀
- url_chapter = 'https://www.17k.com/chapter/'+l+'.html'
- flag += 1
- print(url_chapter)
- # 获取具体章节的html
- Htmlcode = get_htmlcode(url_chapter)
- # 从章节的html中得到章节名
- Subject = get_subject(Htmlcode)
- Temp = insert_lock(Htmlcode)
- if Temp == -1:
- # 从html中得到小说
- Novel = get_novel(Htmlcode)
- # 输入到最终TXT中
- path.write(str(Subject))
- path.write('\n')
- for j in Novel:
- path.write(' ')
- path.write(j)
- path.write('\n')
- path.write('\n\n')
- # 加一个提示信息
- print('章节%s %s打印结束' % (Novel_name_str, Subject))
- # 短暂随机休息,防止被网站后台封禁
- time.sleep(round(random.uniform(0.2, 0.5), 2))
- else:
- print('章节%s爬取失败'%Subject)
- path.write('\n')
- path.write(str(Subject))
- path.write('\n')
- path.close()
- print('小说%s爬取完成' % Novel_name_str)
-
这其中有一些调用的自定义方法和上一个帖子中的基本一致,因为爬取的是不同的小说网站,所以无非是正则表达式的写法会不同而已。相信跟着一起做过的同学都是没问题的。
使用了threading中的Thread方法启动多线程。
在考虑启动多少个线程时,我纠结了一会。一方面是担心线程数太多的话,会被网站封禁,并且本机的网络和性能都会收到影响;另一方面又担心线程数太少的话,效率不高。
想多了之后,心里也把不住个结果。总共就500部小说不到,干脆就遍历列表,有多少元素就启动多少个线程。于是试运行了下,发现效果挺好的。
正好也合了那句话:重剑无锋,大巧不工。顺其自然,别打磨的太繁琐。
- if __name__ =='__main__':
- Htmlcode_Freetop = get_htmlcode(url_list)
- #获取免费榜单所有小说的url
- Topfree_List = get_topfree_list(Htmlcode_Freetop)
- #循环启动多进程,设置间隔时间
- for i in Topfree_List:
- threading.Thread(target=get_novel_all, args=(i,)).start()
- time.sleep(0.5)
- print('免费榜单上的所有txt已爬取完成')
-
- import os
- import requests
- import re
- import time
- import random
- import threading
-
- #创建目录
- if not os.path.exists('Txt'):
- os.mkdir('Txt')
-
- #获取网页html
- def get_htmlcode(url):
- try:
- urlhtml = requests.get(url)
- htmlcode = urlhtml.content
- # path = open('Txt/html.txt','wb')
- # path.write(htmlcode)
- # path.close()
- except:
- htmlcode = 'error'
- return htmlcode
-
- #获取所有免费top榜的txt地址,去重,再完善地址路径
- def get_topfree_list(htmlcode):
- reg = '</a></td><td><a class="red" href="(.+?)" title='
- reg_msg = re.compile(reg)
- list_all = reg_msg.findall(htmlcode.decode())
- #去重
- list_temp = list(set(list_all))
- list_top = []
- #完善地址,加上https前缀,并将book替换成list
- for i in list_temp:
- i = 'https:'+ i
- i = i.replace('book','list')
- list_top.append(i)
- return list_top
-
- #获取小说名称
- def get_novel_name(htmlcode):
- reg = '<h1 class="Title">(.+?)</h1>'
- reg_msg = re.compile(reg)
- novel_name = reg_msg.findall(htmlcode.decode())
- return novel_name
-
- #获取章节地址列表(无https:前缀)
- def get_chapter_list(htmlcode):
- htmldecode = htmlcode.decode()
- reg = r'href="/chapter/(.+?).html'
- reg_msg = re.compile(reg)
- chapter_list = reg_msg.findall(htmldecode)
- return chapter_list
-
- #获取章节名称
- def get_subject(htmlcode):
- reg = '<h1>(.+?)</h1>'
- reg_msg = re.compile(reg)
- subject = reg_msg.findall(htmlcode.decode())
- return subject
-
- #获取正文,需要先切割再正则
- def get_novel(htmlcode):
- htmldecode = htmlcode.decode()
- a = htmldecode.index('<div class="p">')
- b = htmldecode.index('<p class="copy ">')
- htmldecode_final = htmldecode[a:b]
- reg = '<p>(.+?)</p>'
- reg_msg = re.compile(reg)
- novel = reg_msg.findall(htmldecode_final)
- return novel
-
- #判断是否被锁定
- def insert_lock(htmlcode):
- str1 =htmlcode.decode()
- str2 ='<h1>该章节已被锁定</h1>'
- temp = str1.find(str2)
- return temp
-
- #从小说章节列表地址到爬取完成
- def get_novel_all(chapter_url):
- # 章节列表网站的html
- Htmlcode_chapter_list = get_htmlcode(chapter_url)
- if Htmlcode_chapter_list == 'error':
- print('~~~~~~~~~~~~~17K小说地址出错了:%s,请稍后再试~~~~~~~~~~~~~'%chapter_url)
- else:
- # 获取小说名称
- Novel_name = get_novel_name(Htmlcode_chapter_list)
- Novel_name_str = str(Novel_name)
- # 从源码中匹配出所有章节的地址
- Chapter_list = get_chapter_list(Htmlcode_chapter_list)
- # 创建TXT文件并打开
- path = open('17k/' + Novel_name_str + '.txt', 'a',encoding='utf-8')
- # 写入小说名称
- path.write('~~~~~~%s~~~~~~' % Novel_name_str)
- path.write('\n\n\n')
- flag = 0
- # 循环处理每个章节地址
- for l in Chapter_list:
- # 逐一处理章节地址,加上前缀
- url_chapter = 'https://www.17k.com/chapter/'+l+'.html'
- flag += 1
- print(url_chapter)
- # 获取具体章节的html
- Htmlcode = get_htmlcode(url_chapter)
- # 从章节的html中得到章节名
- Subject = get_subject(Htmlcode)
- Temp = insert_lock(Htmlcode)
- if Temp == -1:
- # 从html中得到小说
- Novel = get_novel(Htmlcode)
- # 输入到最终TXT中
- path.write(str(Subject))
- path.write('\n')
- for j in Novel:
- path.write(' ')
- path.write(j)
- path.write('\n')
- path.write('\n\n')
- # 加一个提示信息
- print('章节%s %s打印结束' % (Novel_name_str, Subject))
- # 短暂随机休息,防止被网站后台封禁
- time.sleep(round(random.uniform(0.2, 0.5), 2))
- else:
- print('章节%s爬取失败'%Subject)
- path.write('\n')
- path.write(str(Subject))
- path.write('\n')
- path.close()
- print('小说%s爬取完成' % Novel_name_str)
-
- url_list = 'https://www.17k.com/top/refactor/top100/06_vipclick/06_click_freeBook_top_100_pc.html'
-
- if __name__ =='__main__':
- Htmlcode_Freetop = get_htmlcode(url_list)
- #获取免费榜单所有小说的url
- Topfree_List = get_topfree_list(Htmlcode_Freetop)
- #循环启动多进程,设置间隔时间
- for i in Topfree_List:
- threading.Thread(target=get_novel_all, args=(i,)).start()
- time.sleep(0.5)
- print('免费榜单上的所有txt已爬取完成')
-
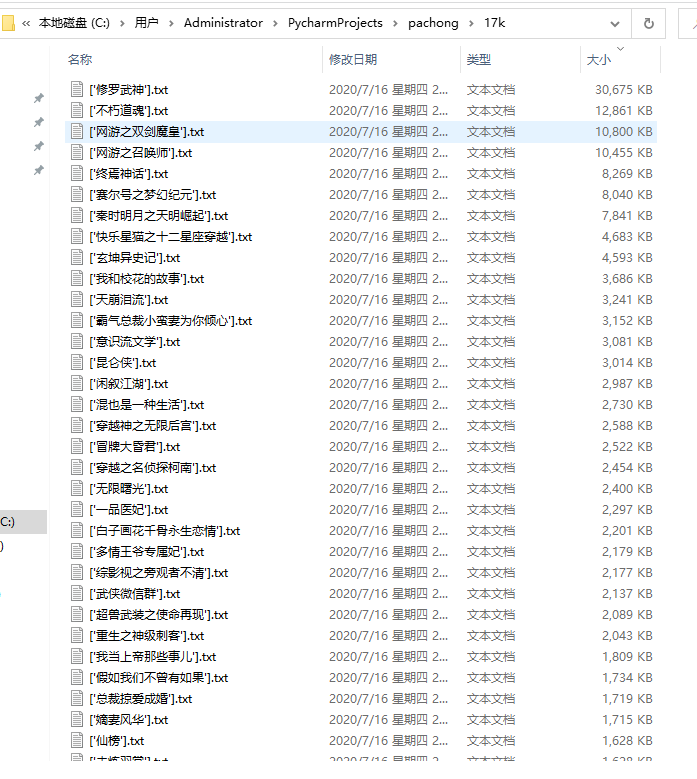
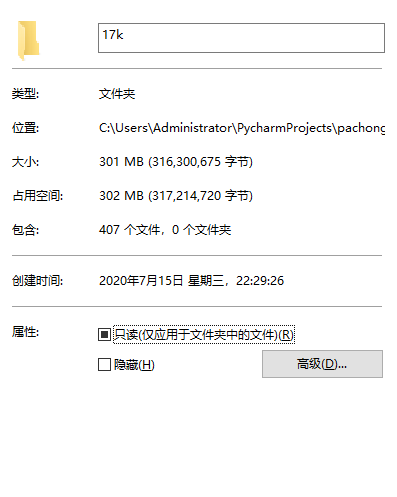
总共407部小说,脚本跑大概15分钟后,爬完了405部,总共有300M。有两部因为章节数太多,一个是快5千章,另一个是接近上万章,所以提前结束了进程,没跑完。最后剩下的那部小说是正则表达式没有找到章节名,线程报错而停止了,可能是又有一个类似锁定的其他结构吧。(只不过我也懒得再去纠结了,哈哈哈~)至少从整体正确性和效率性上来看,爬虫工具的任务完成得还算及格。
想起前不久,有个朋友开玩笑要不要把抖音APP上小姐姐的视频爬下来。我想了下思路,可能是得先用fiddler类似的代理工具抓一下APP访问的地址,然后后面的事情就大同小异了。我这样一说可能似乎是很简单,其实真要做的话,还是会遇到不少困难。
只不过那又有什么好担心的呢?在研究的道路上,摸着石头过河并不可笑,可笑的是连水都不愿意下。



 湘公网安备 43102202000103号
湘公网安备 43102202000103号








