SourceForge与Github类似,是一套合作式软件开发管理系统,上面有大量的开源项目——这是Wiki百科的描述。然而在我的印象里,它只是个广告一堆下载速度贼慢找半天找不到下载链接在哪的网站;以前在它上面下载过几次东西体验极差,这次又有了需求(找遍了网上只有这一个地方能下载)
最近在学pyfoam的用法,正好看到OpenFOAM有个workshop讲的很详细,然而源文件没有,于是来到了这个网址https://sourceforge.net/projects/openfoam-extend/files/OpenFOAM_Workshops/进行下载,发现了历年的讲座都有!这么好的资源当然要下载下来。然而面对着这一层层的文件夹SourceForge竟然不让你直接下载,只能点进去一个个文件下载(这要点到什么时候)。

这就算了,每当你下载一个文件时不时会让你等个5s

迅速得出结论:这是个练习爬虫的好机会。
开工开工,首先打开Chrome或Firefox浏览器调出控制台,查看HTML代码。

可以发现在<th scope="row" headers="files_name_h">下有我们想要的文件夹的相对链接,而且每一层的结构都类似,故可以通过正则表达式轻易地定位到该部分。
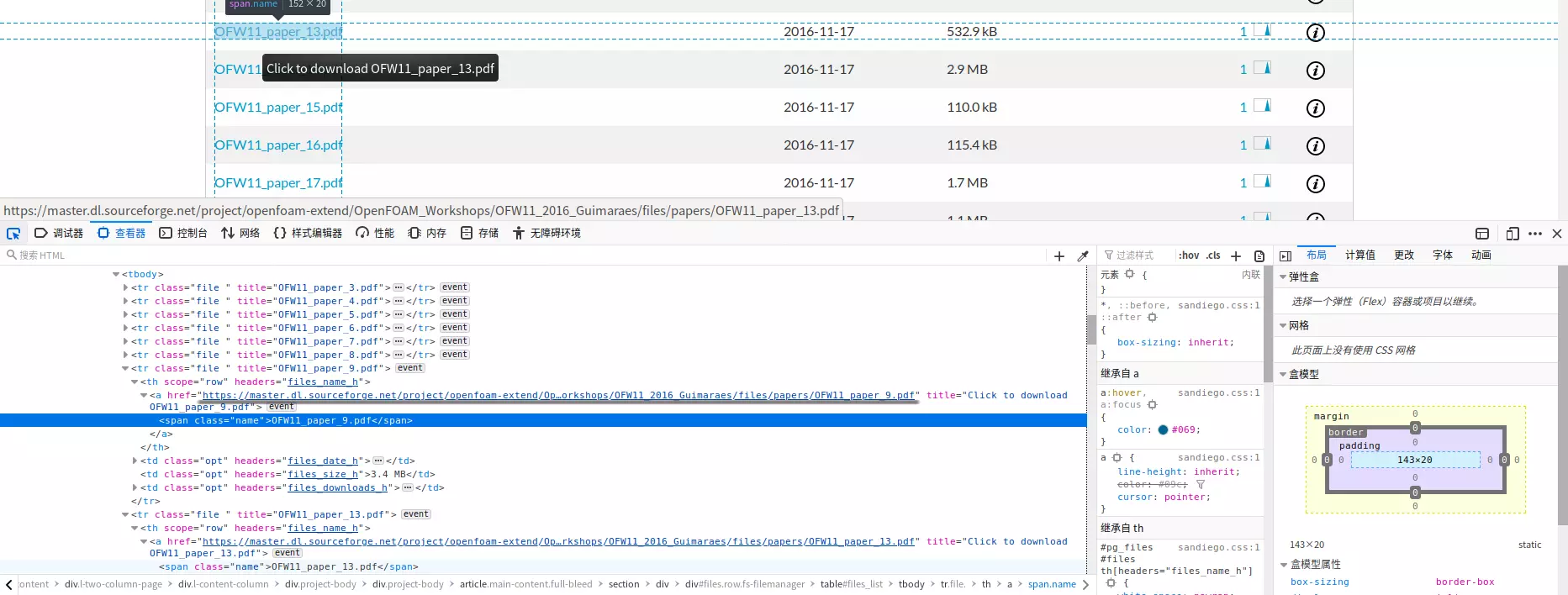
前面的多级文件夹都是采用的相对链接,而到最后每个文件可以看到肯定是有个绝对链接的,点击该href就能下载。
前面的都找到之后就可以编py程序了,因为每个文件夹下都可能有文件和文件夹并存,最好先把文件结构建立起来。利用相对链接建立文件夹,再把相应的绝对链接储存在文本文件中,以便下一步下载。
python3环境,采用requests库,引入多个header随机切换,设定一小段休眠时间,通过嵌套的函数建立层层文件夹:
getlinks.py
- # coding=utf-8
- import requests
- import re
- import os
- import random
- import time
-
- my_headers = [
- "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
- "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
- 'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
- 'Opera/9.25 (Windows NT 5.1; U; en)',
- 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
- 'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
- 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
- 'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
- "Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
- "Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
- ]
-
-
- def find_and_print_links(html):
- headers = {
- 'User-Agent': random.choice(my_headers)
- }
- response = requests.get(html, headers=headers)
- pattern = re.compile('<th scope="row" headers="files_name_h"><a href="(.*?)"', re.S)
- downloadurl = re.findall(pattern, str(response.text))
- for item in downloadurl:
- t = 0.1
- time.sleep(t)
- if re.findall('https:', item) == []:
- if not os.path.exists('.' + item):
- os.makedirs('.' + item)
- html = 'https://sourceforge.net' + item
- find_and_print_links(html)
- else:
- path = '.' + re.findall('(/projects/.*)/.*/download', item)[0]
- if not os.path.exists(path):
- os.makedirs(path)
- with open(path + '/' + 'links.txt', 'a') as f:
- f.write(str(item))
- f.write('\n')
- f.close()
-
-
- if __name__ == '__main__':
- html = "https://sourceforge.net/projects/openfoam-extend/files/OpenFOAM_Workshops/"
- find_and_print_links(html)
为了防止程序中途出错下次重头开始,设置了一个if条件判断当前文件夹是否已经生成;我大概运行了几分钟就建立好了全部的文件夹并获得了所有下载链接。

os.walk命令能够读取文件夹里的所有文件并很容易转化成一个List,之后只需要判断每个item里是否含有文本文件,有就逐一下载到本地。
下载采用的是非常强大的下载利器you-get,什么Youtube、B站上的视频音频通通一个命令就能下载。
downloadfiles.py
- import re
- import os
-
- def findlinks_and_download(item):
- current = os.getcwd()
- path = re.findall('(.*?)\\\\links.txt', item)[0]
- # If you use linux, change the '\\\\' to '/'
- os.chdir(path)
- f = open('links.txt', 'r')
- for line in f.readlines():
- filename_with_suffix= re.findall('https://sourceforge.net/projects.*/(.*?)/download',line)[0]
- if not os.path.exists(filename_with_suffix):
- os.system("you-get " + "-O"+filename_with_suffix+" "+ line )
- os.chdir(current)
-
-
- if __name__ == '__main__':
- g = os.walk('.')
- files = []
- for path, dir_list, file_list in g:
- for file_name in file_list:
- files.append(os.path.join(path, file_name))
- for item in files:
- if re.findall('links.txt', item) == []:
- continue
- else:
- findlinks_and_download(item)
短短几十行代码就能够解决我的需求,而且今后遇到要在sourceforge下载东西时直接拿来用就行。(好在sourceforge没有什么反爬措施,我基本上没遇到被403或其他访问失败的情况)

下是下好了,接下来就是一段漫长的学习了…



 湘公网安备 43102202000103号
湘公网安备 43102202000103号








